【EUSIPCO 2024】「よく似た音」を利用し、異音検知する教師なしモデルの高精度化と学習計算量の削減を実現する手法を提案

信号処理分野におけるトップカンファレンス「EUSIPCO 2024」にて主著論文が採択

クルマとモビリティ社会全体の未来を見据え、「種」となる先端基礎研究を行う株式会社デンソーアイティーラボラトリ(本社:東京都港区 代表取締役社長:岸本正志)の研究者である太刀岡勇気による論文「Outlier Exposure with Efficient Division of Positive and Negative Examples for Anomalous Sound Detection」が、2024年8月にフランス・リヨンで開催された「European Signal Processing Conference(EUSIPCO 2024)」に採択されました。EUSIPCO は信号処理分野における国際的なトップカンファレンスの一つで、デジタル信号処理、画像処理、音声処理、通信、マルチメディア、データ圧縮、機械学習、データ解析など幅広い分野の研究成果が発表されています。
本研究では、機械の異常音を検知するモデルの精度を効率よく向上させる手法を提案しました。異常音検出では、異常音データの入手が難しいため、教師なし学習で異常音検知モデルを学習し、高精度に異常音を検出することが課題となっています。
従来の手法では、ある機種(対象機種)の異常音を判定する際には、その機種の正常音と他の機種の正常音を区別するようにモデルを学習して、正常音か異常音かを判定します。一方、今回提案した手法では、対象機種の異常音判定に有効な他の機種の正常音を判別し、複数の機械の正常音を対象機種の正常音とみなして学習することで、異常音検知の精度向上を実現しました。正常音に加える機種の判別には膨大な計算を必要とすることが課題ですが、提案法ではこれを効率的に行うことができます。
この研究成果を応用して、工場などに設置された設備機械の異常音検知に有用な、現場環境における異常音検知モデルの構築を効率的に行えるようになることが期待できます。
■研究の背景
対象とする機械(以下対象機種)から発せられる音が正常か異常かを識別する異常音検知(ASD)は、工場の製造機械の故障を早期に検知するための重要な技術です。現実の工場では、異常はめったに発生せず、しかも異常の種類は多様なので異常音の種類も多様となります。学習用のデータとして異常音を入手することは困難であり、また、学習済みモデルは学習用データに含まれない異常音を検知する必要があります。この課題に対応するために、教師なし学習による異常音検知(教師なしASD)の手法が求められています。
教師なしASDの手法は、大きくinlier modeling(IM)とoutlier exposure(OE)に分けられます。IMは、対象機種の正常音の確率分布を作成して、分布から外れた音を異常音と識別します。OEは対象機種とは別の機種の正常音も学習データとして使用し、対象機種の正常音と他の機種の正常音を正例と負例として分類します。OEベースのモデルはIMベースのモデルに比べて精度の振れ幅が大きいため、ロバスト性を持たせるために、前段にOEベースの特徴抽出器を置き、そこで得られた特徴量を後段のIMに投入して正規データの確率分布を作成する2段階ASDが提案されています。

今回の研究成果としてまず、前段の特徴抽出器に対象の機種以外の機種の正常音を正例として同時に学習させるマルチコンディション学習によって、ASDの精度が向上する場合があることを実験的に示しました。しかしどの機種のデータを正例に追加するのが最適かを決定するために、全ての組み合わせを試すのは、モデルの数が増えすぎて現実的ではありません。ASDの精度を向上するために、正例に追加すべき機種のデータを効率的に選択する方法が課題となります。
■本研究の成果
本研究では、対象機種とよく似た特徴の音を出す機種の正常音を正例に追加し、そうではない機種の正常音は負例として学習させることで、ASDの精度が上がるという仮説を立てました。
仮説を検証するために、まず、対象機種の正常音を正例、それ以外の音を負例として、ベースラインモデルを作成します。
この分類器は、正例と負例を識別し、なおかつ正例はコンディションID(収音環境を表すID)を識別できるように学習します。このモデルは、正例と負例の埋め込みベクトルが離れているという仮定に基づきます(図左)。別の機種の正常音も正例に追加して学習する場合、追加されたのがよく似た特徴を持つ音であれば、その音のベクトルは同様に負例から分離されると考えられます。(図右)
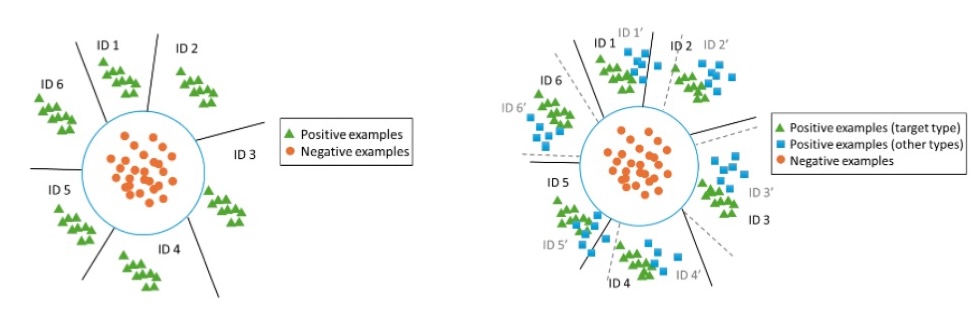
「対象機種と似た特徴を持つ音」を探すために、本研究では、機種ごとに作成したベースラインモデルを使用します。
使用したデータは、DCASE Challenge 2022 (※)で提供された7種類の機械(ベアリング、ファン、ギアボックス、スライダー、バルブ、トイカー、トイトレイン)のデータです。7種類の機械それぞれのテストデータに対し、7種類のベースラインモデルで異常音検知を行います。
※DCASE Challenge:音響シーンやイベントの検出と分類に関する国際的な競技会
表1の行は学習に用いた機種、列はテストに用いた機種です。表の対角成分はベースラインの学習とテストの機種が一致しているケースですが、それ以外は不一致のケースです。正例として学習に使用した機種と同じ機種の異常音を最も性能よく検知するように思えますが、実際には不一致の方が精度が上がるケースもあります。例えばベアリングで学習したモデルは、ベアリングよりも他の機種の方が異常音検知精度が高くなっています。

本研究では、機種が不一致の場合の方が精度が高くなるケースがあった「ベアリング」「ファン」「トイトレイン」を、正例として他の機種のモデルにも追加しました。ベースラインモデルと本研究で提案するモデルを比較すると、トイカー以外の6つの機種では異常音検知の精度が上がることが示せました。

ところでn種類の機種の中からどの機種を正例に含めるか決める組み合わせは、n×2(n-1)通りあります。単純に最適な組み合わせを選ぶには、この数のモデルを学習し、評価する必要がありますが、提案した手法によってあらかじめ表1のn個のモデルに対してn回の評価(=全部でnの2乗回の評価)行っておくことで、どの機種を正例に含めるかを決められるので、モデルの学習は追加のn回で済みます。
これにより、ほとんど通常の機種ごとに学習する方法と変わらない計算量まで減らすことができ、かつ、異常音検知の精度が向上することが示せました。この例では、ナイーブな方法では7種類の機械それぞれについて正例に含める機種を選ぶ組み合わせは 7×26=448通りあるのでその回数分モデルの学習と評価が必要ですが、提案した方法では7×7=49通りのモデルを評価し表1を作成したのちに7機種分のモデル学習を行えば良いことになります。

■本研究の論文
Yuuki Tachioka “Outlier Exposure with Efficient Division of Positive and Negative Examples for Anomalous Sound Detection”, in 32th European Signal Processing Conference
■今後の展開
今回の研究発表では、2段階ASDにおける特徴抽出器について、改良を行い精度を上げるための効率的な方法を提案しました。工場の製造機械の異常音検知においては、設置された環境による音の違いを学習する必要があります。今回の研究成果を活かすことで、より精度の高いモデルを、短時間の学習で構築することが期待できます。また、自動車の点検依頼で最も多い「異常音」は、通常の使用時に発生していても別の環境では再現が難しいことがあります。本研究を生かして、自動車の収音センサーのデータを利用したタイムリーな異常音検知の実現と予防保守の提案など、より安心・安全な自動車の実現への貢献が期待できます。
■株式会社デンソーアイティーラボラトリとは
デンソーグループのソフトウェア研究を担う25人ほどの研究者集団であり、「自分たちで課題を見つけ、それを解決する技術の柱を作る」シーズ提案型の先端基礎研究企業です。研究分野には、深層学習やニューラルネットワーク、画像認識、自然言語処理、認知科学、信号処理、ユーザーインターフェース、センシング技術、量子コンピュータなどがあります。株式会社デンソーの100%出資子会社となります。
■問い合わせ先
デンソーアイティーラボラトリ広報事務局(エポックシード) 森下
電話:03‐3407‐5780 メール:press@epochseed.jp
